LLMs as Building Blocks for Next-Gen Software
Large Language Models (LLMs) are transforming the software industry with their sophisticated natural language processing and understanding capabilities. As essential components in the development of next-generation software, LLMs are increasingly relevant to the future of programming. This blog post will explore the potential of LLMs in-depth, from GitHub repositories like Langchain to the use of vector search databases and the concept of self-reflection in LLM agent compositions. However, it's important to remain aware of the limitations of LLMs and the role of human oversight in ensuring their reliability.
LLMs, such as OpenAI's GPT series, have opened new horizons in the software industry, enabling developers to create advanced and versatile applications. LLMs are pretrained on massive datasets and can process and generate human-like text, allowing them to understand and respond to complex inputs. This functionality makes LLMs a valuable building block for creating next-generation software solutions that are efficient, intelligent, and adaptable to various use cases, including chatbots, code generation, and content creation.
Langchain is a GitHub repository that streamlines the integration of LLMs with traditional software. By providing a platform for developers to compose software using LLMs, Langchain enables the creation of powerful applications that harness the full potential of these models. For example, Langchain allows developers to create intelligent code generation tools by combining LLMs with syntax-aware models, resulting in software that can generate code snippets based on natural language input while maintaining syntactic correctness.
Vector search databases, such as FAISS or PineconeDB, play a crucial role in augmenting the capabilities of LLMs. These databases store and retrieve high-dimensional data vectors, allowing LLMs to quickly and accurately process information. By incorporating vector search databases into LLM-based software, developers can improve performance and efficiency while expanding the potential applications of their creations. For instance, LLMs can be combined with vector search databases to develop advanced recommendation systems that analyze user preferences and generate personalized content.
Self-reflection is a key aspect of LLM agent compositions, enabling models to analyze and evaluate their own behavior. This introspection allows LLMs to learn from their mistakes and become more reliable over time. For example, incorporating self-reflection into the design of LLMs can help create intelligent agents that adapt and grow in response to user feedback or new data. This results in more robust and dependable software solutions that better serve the needs of users in various domains, from customer support to healthcare.
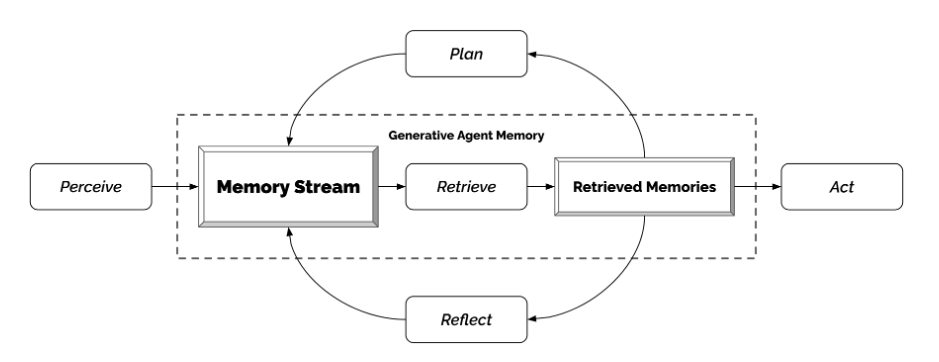
Generative agent architecture. Source: https://arxiv.org/pdf/2304.03442.pdf
While LLMs have many practical applications, they can also be used creatively to push the boundaries of software development. For example, LLMs can be employed in the creation of Non-Player Character (NPC) world simulations in gaming, generating lifelike interactions and immersive environments. Developers can use LLMs to simulate dialogues, generate storylines, or even create in-game tutorials that dynamically adapt to player choices. This is just one of the many inventive ways LLMs can be used, and developers are encouraged to think outside the box when considering their potential applications.
Despite their impressive capabilities, it's important to recognize the limitations of LLMs. Many examples showcased on Twitter often display the "happy paths" of LLMs, but in reality, these models are not always reliable. For instance, LLMs can generate inappropriate or biased content due to the nature of their training data. Human oversight is essential in the development process to ensure the quality and accuracy of LLM-based software. Implementing strategies such as rule-based filters, reinforcement learning from human feedback, or fine-tuning LLMs on specific domain data can help mitigate these limitations.
It's crucial to maintain a realistic perspective and be cautious of skewed perceptions when evaluating the true potential of LLMs. For instance, when developing AI-based moderation tools, it is essential to recognize that LLMs alone cannot guarantee perfect content filtering, and human moderators are still needed to make the final call in ambiguous cases.
LLMs have undoubtedly emerged as a powerful building block for the next generation of software. With innovative platforms like Langchain and the incorporation of vector search databases, LLMs are poised to transform the software industry. However, it's crucial to recognize their limitations and the importance of human oversight in ensuring their reliability. As developers continue to experiment and explore the potential of LLMs, we can anticipate the emergence of groundbreaking software solutions that will shape the future of technology. By balancing the excitement around LLMs with a healthy dose of realism, we can truly unlock their full potential and create a better, more intelligent digital landscape.